SQL必知必会学习笔记(二)
学极客时间的 SQL必知必会专栏,做记录(数据过滤、SQL函数、子查询)
-- SQL 的书写规范:
-- 关键字和函数名称全部大写;
-- 数据库名、表名、字段名称全部小写;
-- SQL 语句必须以分号结尾。数据过滤
WHERE 条件
不同的 DBMS 支持的运算符可能是不同的,比如 Access 不支持(!=),不等于应该使用(<>);在 MySQL 中,不支持(!>)(!<)等。
| 含义 | 运算符 |
|---|---|
| 等于 | = |
| 不等于 | <>或!= |
| 小于 | < |
| 小于等于(不大于) | <=或!> |
| 大于 | > |
| 大于等于(不小于) | >=或!< |
| 不小于 | !< |
| 指定的两个值之间 | BETWEEN |
| 为空值 | IS NULL |
WHERE 子句的基本格式是:SELECT ……(列名) FROM ……(表名) WHERE ……(子句条件)。 当 WHERE 子句中同时存在 OR 和 AND 的时候,AND 执行的优先级会更高,也就是说 SQL 会优先处理 AND 操作符,然后再处理 OR 操作符。
通配符
通配符就是我们用来匹配值的一部分的特殊字符。这里我们需要使用到 LIKE 操作符。如果我们想要匹配单个字符,就需要使用下划线 _ 通配符。% 和 _ 的区别在于, % 代表零个或多个字符,而 _ 只代表一个字符,这个和正则表达式很像。在 Access 中使用的是 * 而不是 % , 使用 ? 而不是 _ ;DB2 中不支持通配符 _。需要对应各自 DBMS 的文档使用
SQL:SELECT name FROM heros WHERE name LIKE '%太%'通配符的使用需要消耗数据库更长的时间来进行匹配。即使你对 LIKE 检索的字段进行了索引,索引的价值也可能会失效。如果要让索引生效,那么 LIKE 后面就不能以 % 开头,比如使用 LIKE '%太%' 或 LIKE '%太' 的时候就会对全表进行扫描。如果使用 LIKE '太%' ,同时检索的字段进行了索引的时候,则不会进行全表扫描。
GROUP BY 分组
SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist ORDER BY num DESC可以使用一个或多个字段进行分组,相当于把这些字段可能出现的所有的取值情况都进行分组.如果字段为 NULL,也会被列为一个分组。使用 GROUP BY 进行分组,如果想让输出的结果有序,可以在 GROUP BY 后使用 ORDER BY。因为 GROUP BY 只起到了分组的作用,排序还是需要通过 ORDER BY 来完成。
HAVING 过滤分组
SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist HAVING num > 5 ORDER BY num DESC对于分组的筛选,我们一定要用 HAVING,而不是 WHERE,如果把 HAVING 替换成了 WHERE,SQL 会报错。另外 HAVING 支持所有 WHERE 的操作,因此所有需要 WHERE 子句实现的功能,你都可以使用 HAVING 对分组进行筛选。
SQL 函数
SQL 中的函数一般是在数据上执行的,可以很方便地转换和处理数据。一般来说,当我们从数据表中检索出数据之后,就可以进一步对这些数据进行操作,得到更有意义的结果,比如返回指定条件的函数,或者求某个字段的平均值等。
不同的 DBMS 支持的函数是有差异的,所以采用函数的 SQL 的移植性是很差的,但如果是使用单一 DBMS 的话,还是很方便的。
算术函数
| 函数名 | 定义 |
|---|---|
| ABS() | 取绝对值 |
| MOD() | 取余 |
| ROUND() | 四舍五入为指定的小数位数,需要有两个参数,分别为字段名称和小数位数 |
字符串函数
| 函数名 | 定义 |
|---|---|
| CONCAT() | 将多个字符串拼接起来 |
| LENGTH() | 计算字段的长度,一个汉字算三个字符,一个数字或一个字母算一个字符 |
| CHAR_LENGTH() | 计算字段的长度,汉字、字母、数字都算一个字符 |
| LOWER() | 将字符串中的字符转化成小写 |
| UPPER() | 将字符串中的字符转化成大写 |
| REPLACE() | 替换函数,有三个参数:要替换的表达式或字段名,想要查找的被替换字符串,替换成哪个字符串 |
| SUBSTRING() | 截取字符串,有三个参数:待截取的表达式或字段名,开始截取的位置,想要截取的字符串长度 |
日期函数
| 函数名 | 定义 |
|---|---|
| CURRENT_DATE() | 系统当前日期 |
| CURRENT_TIME() | 系统当前时间,没有具体的日期 |
| CURRENT_TIMESTAMP() | 系统当前时间,包括具体的日期+时间 |
| EXTRACT() | 抽取具体的年、月、日 |
| DATE() | 返回时间的日期部分 |
| YEAR() | 返回时间的年份部分 |
| MONTH() | 返回时间的月份部分 |
| DAY() | 返回时间的天数部分 |
| HOUR() | 返回时间的小时部分 |
| MINUTE() | 返回时间的分钟部分 |
| SECOND() | 返回时间的秒部分 |
转换函数
| 函数名 | 定义 |
|---|---|
| CAST() | 数据类型转换,参数是一个表达式,表达式通过AS关键词分割了两个参数,分别是原始数据和目标数据类型。注意在转换的时候不会四舍五入,小数转整数会报错。 |
| COALESCE | 返回第一个非空数值 |
聚集函数
| 函数 | 说明 |
|---|---|
| COUNT() | 总行数 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| SUM() | 求和 |
| AVG() | 平均值 |
COUNT(字段名) 会忽略值为 NULL 的数据行,而 COUNT(*) 只是统计数据行数,不管某个字段是否为 NULL。AVG、MAX 、MIN 等聚集函数会自动忽略值为 NULL 的数据行,MAX 和 MIN 函数也可以用于字符串类型数据的统计,如果是英文字母,则按照 A—Z 的顺序排列,越往后数值越大;如果是汉字则按照全拼拼音进行排列。
一般我们使用 MAX 和 MIN 函数统计数据行的时候,不需要再额外使用 DISTINCT,因为使用 DISTINCT 和全部数据行进行最大值、最小值的统计结果是相等的。
子查询
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做非关联子查询。同样,如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为关联子查询。
SELECT player_name, height, team_id FROM player AS a WHERE height > (SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id)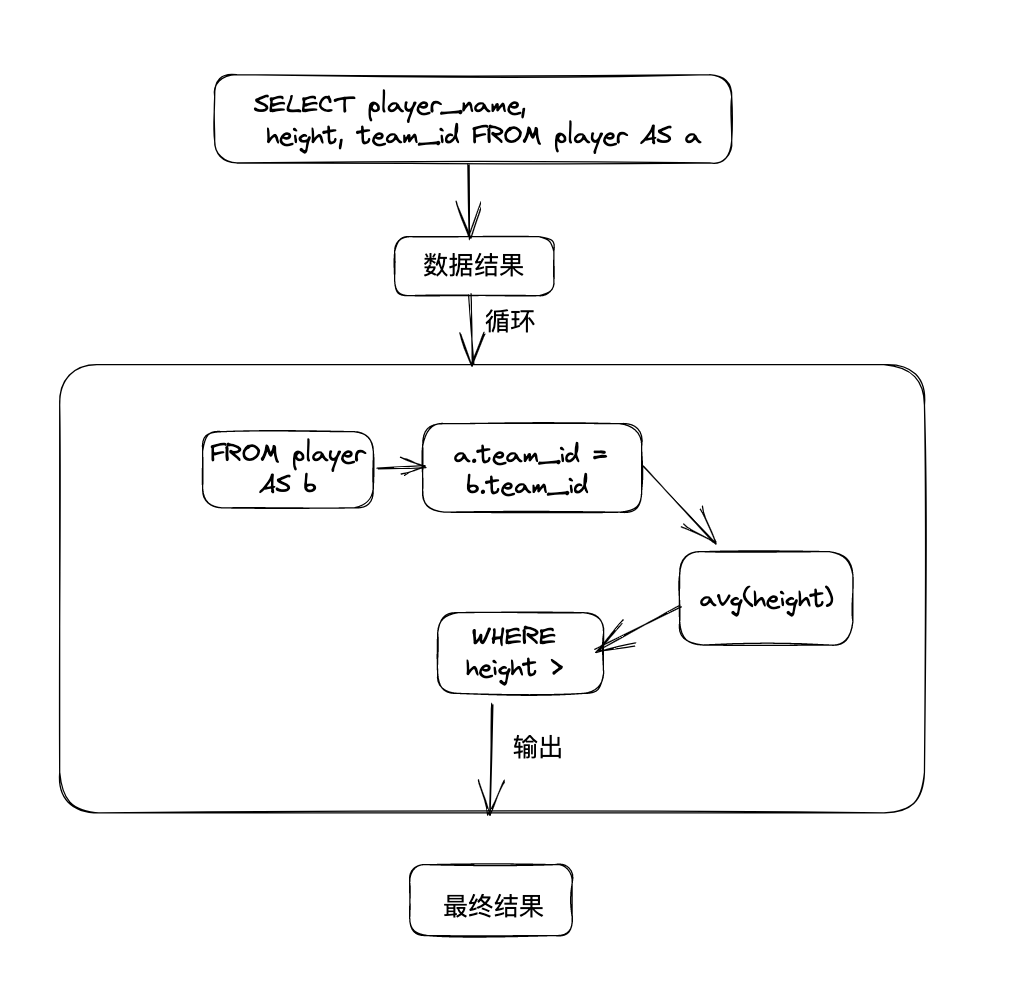
关联查询示例:先从 a 表中取出 player_name, height, team_id 三个字段的所有数据行,然后循环对每行数据执行子查询,在 b 表中查询所有team_id 等于当前数据行的,算出他们的 height 平均值,外部查询再执行 WHERE 判断 height 是否大于这个值。每次外部查询依赖的子查询的值都需要重新计算
EXISTS 子查询
关联子查询通常也会和 EXISTS 一起来使用,EXISTS 子查询用来判断条件是否满足,满足的话为 True,不满足为 False。同样,NOT EXISTS 就是不存在的意思。
-- SQL示例
SQL:SELECT player_id, team_id, player_name FROM player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
SQL: SELECT player_id, team_id, player_name FROM player WHERE NOT EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)集合比较子查询
| 字段 | 说明 |
|---|---|
| IN | 判断是否在集合中 |
| ANY | 需要与比较操作符一起使用,与子查询返回的任何值做比较 |
| ALL | 需要与比较操作符一起使用,与自冲洗返回的所有值做比较 |
| SOME | 实际上是 ANY 的别名,作用相同,一般常使用 ANY |
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc)实际上在查询过程中,在我们对 cc 列建立索引的情况下,我们还需要判断表 A 和表 B 的大小。如果表 A 比表 B 大,那么 IN 子查询的效率要比 EXIST 子查询效率高,因为这时 B 表中如果对 cc 列进行了索引,那么 IN 子查询的效率就会比较高。同样,如果表 A 比表 B 小,那么使用 EXISTS 子查询效率会更高,因为我们可以使用到 A 表中对 cc 列的索引,而不用从 B 中进行 cc 列的查询。
将子查询作为计算字段
SQL: SELECT team_name, (SELECT count(*) FROM player WHERE player.team_id = team.team_id) AS player_num FROM team